AI-Powered Internal Document Search App (RAG Prototype)
Overview
This project is a prototype of a Retrieval Augmented Generation (RAG) search application developed for LixCap to enhance research capabilities across an extensive internal document library. The application demonstrates how RAG technology can significantly improve productivity by delivering highly relevant, semantically-driven search results — overcoming the limitations of traditional keyword-based search. By streamlining access to critical information, the system aims to make internal research faster, more accurate, and far more efficient.
Challenge
• LixCap, a firm specializing in consulting and transaction advisory in emerging markets, possesses a large volume of internal documents. The existing research process relies on syntactic search, which often leads to missed or irrelevant documents, especially if the user is not familiar with the content or specific keywords.
• The current search methods can be highly time-consuming, with some research tasks taking several hours to complete, hindering efficient information retrieval and decision-making.
Solution
• The solution implements a RAG system that moves beyond traditional keyword matching to semantic search. This approach understands the meaning and context of queries, enabling the system to retrieve documents that are conceptually relevant, even if they do not contain exact keyword matches.
Key Features & Functionality
• User Document Upload: Users can easily upload internal documents to the RAG system via a user-friendly interface.
• Broad Document Format Support: The application supports a wide range of common document types, including MS Word, text files, Excel spreadsheets, PowerPoint presentations, PDFs, and Google Docs.
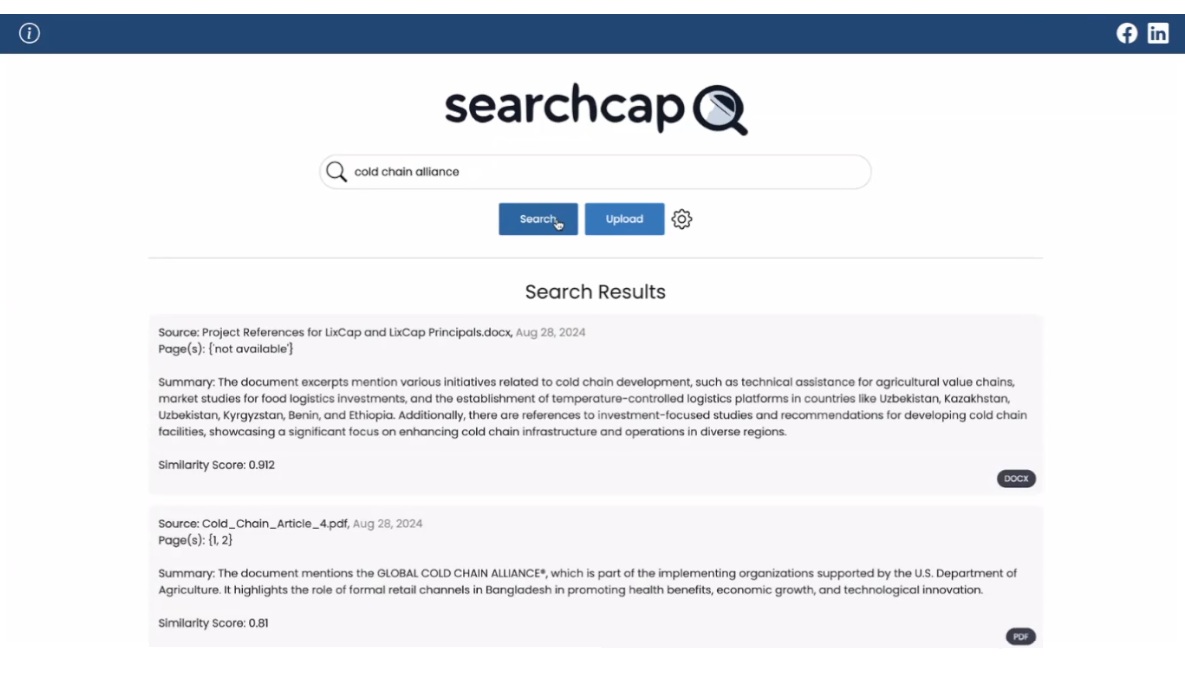
• Semantic Search: Utilizes embeddings to perform intelligent searches within the vector database, identifying and retrieving data that is contextually relevant to the query.
• Relevant Result Display: Presents the top matching documents, ensuring users quickly find the most pertinent information.
• Source Attribution: Clearly indicates the source of the retrieved and summarized results, promoting trust and traceability.
• Improved Search Relevance: A core focus of the prototype is to significantly enhance the accuracy and relevance of search outcomes compared to existing methods.
Technologies Used
• Programming Languages: Python (implied by Shiny/LangChain usage)
• Frameworks/Libraries:
◦ Shiny: For building the interactive user interface (UI).
◦ LangChain: For orchestrating the RAG pipeline, including document processing and interaction with Large Language Models (LLMs) and vector databases.
• Databases:
◦ Qdrant: A high-performance vector database used for storing and searching document embedding.
• APIs/Models:
◦ ChatGPT (OpenAI API): Used for generating document embedding and summarizing search results.
My Role & Contributions
• Document Ingestion Development: I played a key role in writing the code responsible for ingesting documents into the RAG system, ensuring compatibility with various file formats and efficient processing.
• Testing & Quality Assurance: I was actively involved in testing the functionality of the application , from document upload to search relevance and summarization accuracy, contributing to the overall stability and performance of the prototype.
Results & Impact
• Time Savings: The prototype demonstrates the potential to significantly reduce the time spent on internal document research, moving from hours to potentially minutes for complex queries.
• Enhanced Research Accuracy: By leveraging semantic search, the application reduces the risk of overlooking relevant documents due to unfamiliarity with the content library, resulting in more thorough, accurate, and reliable research outcomes.
• Increased Productivity: For LixCap, this tool can directly translate into higher productivity by empowering employees to access critical information quickly and efficiently.
Challenges
• Handling Diverse Document Formats: Ensuring seamless ingestion and processing of various document types (MS Word, Excel, PDFs, etc.) presented specific chunking and parsing challenges.
Future Enhancements
• Integration with existing document management systems (e.g., Dropbox API) for automated ingestion.
• Implementation of user authentication and role-based access control for sensitive documents.
• Advanced filtering and sorting options within the UI.
• Exploration of alternative open-source LLMs and embedding models for enhanced privacy and cost efficiency.